Include client numbers even if we think we got reports from more than 100% of all relays
The estimated fraction of reported user statistics from relays has reached 100% and even went slightly beyond that number to 100.294% on 2018-10-27 and 100.046% on 2018-10-28.
The effect is that we're excluding days when this happened from statistics, because we never thought this was possible:
WHERE a.frac BETWEEN 0.1 AND 1.0However, I think this is most likely a rounding error somewhere, not a general issue with the approach. Stated differently, it seems wrong to include a number with a fraction of reported statistics of 99.9% but not one where that fraction is 100.1%.
I suggest that we drop the upper limit and change the line above to:
WHERE a.frac >= 0.1We'll be replacing these statistics by PrivCount in the medium term anyway.
However, simply excluding data points doesn't seem like an intuitive solution.
Thoughts?
Activity
I wonder if it's more than a rounding error.
How is frac calculated?
I wonder if you're choosing a point in time to calculate the consensus weight fraction.
What happens if relays that submit statistics are offline at that point in time? But it submits statistics later, when it comes back online?
If that relay has a weight N, and 100% of relays submit, then your frac calculation will be:
100 the relays that submitted statistics --------- (100 - N) the relays that were online at the point in time you choseWhen it should be:
100 the relays that submitted statistics --- 100 all the relays that could have submitted statisticsI can't find the codebase or the metrics statistics explanation to check. (I tried searching for the code online. And I tried the metrics wiki pages.)
Edit: formatting

You'll find a description/specification how frac is calculate here: https://metrics.torproject.org/reproducible-metrics.html#relay-users
Maybe rounding error was not the right term. In fact, I believe it might be a situation like the one you're describing. I can extract the variable values going into the frac formula; maybe one of them is responsible for getting us above the 100%.
However, we should carefully consider whether we want to change that formula or rather not touch it until we have PrivCount as replacement. If we think the frac value isn't going to grow much beyond 100%, we could just accept that inaccuracy and live with it. If we think it's going to grow towards, say, 150%, I agree that we'll have to do something.
Replying to karsten:
You'll find a description/specification how frac is calculate here: https://metrics.torproject.org/reproducible-metrics.html#relay-users
Maybe rounding error was not the right term. In fact, I believe it might be a situation like the one you're describing. I can extract the variable values going into the frac formula; maybe one of them is responsible for getting us above the 100%.
I wonder if changing the bandwidth interval to 24 hours revealed this issue?
For servers which report 24 hour intervals, I think that:
h(R^H) is usually equal to h(H) n(H) is usually 24 n(R\H) is usually 0 n(N) can be slightly less than 24, if a relay was unreachable or misconfigured, but didn't go down Therefore, frac can be slightly more than 1.However, we should carefully consider whether we want to change that formula or rather not touch it until we have PrivCount as replacement. If we think the frac value isn't going to grow much beyond 100%, we could just accept that inaccuracy and live with it. If we think it's going to grow towards, say, 150%, I agree that we'll have to do something.
I think a similar analysis applies to PrivCount: if a relay is up for the whole day, then it will report statistics using PrivCount. But if that relay is dropped from some consensuses due to reachability, then our idea of the average number of running relays will be too low.
We won't see this bug until almost all relays are running PrivCount. But let's avoid re-implementing this bug in PrivCount if we can.
What can PrivCount do to avoid introducing a similar bug?
Trac:
Sponsor: N/A to SponsorV-can
Replying to karsten:
I suggest that we drop the upper limit and change the line above to:
{{{ WHERE a.frac >= 0.1 }}}
This sounds like a reasonable thing to do in this case.
-
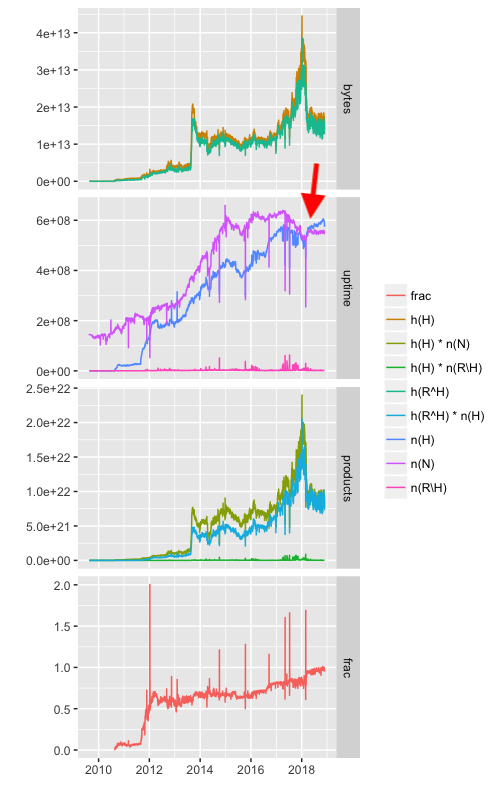
I think I now know what's going on: some relays report written directory byte statistics for times when they were hardly listed in consensuses.
Here's a graph with all variables going into the
fracformula, plus intermediate products, and finally thefracvalue:
Note the red arrow. At this point
n(H)grows larger thann(N). That's an issue. By definition, a relay cannot report written directory bytes statistics for a longer time than it's online.I also looked at random relay
002B024E24A30F113982FCB17DFE05B6F38C0C79that had a largern(H)value thann(N)value on 2018-10-28:- This relay was listed in 3 out of 24 consensuses on 2018-10-28 (19:00, 20:00, and 21:00). As a result, we count this relay with
n(N) = 10800(we're using seconds internally, not hours). - The same relay published an extra-info descriptor on 2018-10-31 at 09:28:04 with the following line:
dirreq-write-history 2018-10-30 08:04:04 (86400 s) 0,0. We count this asn(H) = 57356on 2018-10-28.
A possible mitigation (other than the one I suggested above) could be to replace
n(H)withn(N^H)in thefracformula. This would mean that we'd cap the amount of time for which a relay reported written directory bytes to the amount of time it was listed in the consensus.I'm currently dumping and downloading the database to try this out at home. However, I'm afraid that deploying this fix is going to be much more expensive than making the simple fix suggested above. I'll report here what I find out.
Trac:
Status: new to accepted
Owner: metrics-team to karsten - This relay was listed in 3 out of 24 consensuses on 2018-10-28 (19:00, 20:00, and 21:00). As a result, we count this relay with
Replying to karsten:
I think I now know what's going on: some relays report written directory byte statistics for times when they were hardly listed in consensuses.
Here's a graph ...
Note the red arrow. At this point
n(H)grows larger thann(N). That's an issue. By definition, a relay cannot report written directory bytes statistics for a longer time than it's online.But relays that aren't listed in the consensus can still be acting as relays.
Here are a few scenarios where that happens:
- the relay's IPv4 address is unreachable from a majority of directory authorities, but some clients (with old consensuses) can still reach it:
- the relay's IPv4 address has changed, and the authorities haven't checked the new address, but the relay is still reachable on the old address cached at some clients
- the same scenarios with IPv6, but there are only 6/9 authorities that check and vote on IPv6
- the relay is configured as a bridge by some clients, but it publishes descriptors as a relay
If a relay drops in and out of the consensus every few hours, there will always be some clients with a consensus containing that relay.
I also looked at random relay
002B024E24A30F113982FCB17DFE05B6F38C0C79that had a largern(H)value thann(N)value on 2018-10-28:- This relay was listed in 3 out of 24 consensuses on 2018-10-28 (19:00, 20:00, and 21:00). As a result, we count this relay with
n(N) = 10800(we're using seconds internally, not hours). - The same relay published an extra-info descriptor on 2018-10-31 at 09:28:04 with the following line:
dirreq-write-history 2018-10-30 08:04:04 (86400 s) 0,0. We count this asn(H) = 57356on 2018-10-28.
A possible mitigation (other than the one I suggested above) could be to replace
n(H)withn(N^H)in thefracformula. This would mean that we'd cap the amount of time for which a relay reported written directory bytes to the amount of time it was listed in the consensus.This seems like a reasonable approach: if the relay is listed in the consensus for
n(N^H)seconds, then we should weight its bandwidth using that number of seconds.I'm currently dumping and downloading the database to try this out at home. However, I'm afraid that deploying this fix is going to be much more expensive than making the simple fix suggested above. I'll report here what I find out.
I'm not sure if it will make much of a difference long-term: relays that drop out of the consensus should have low bandwidth weights, and therefore low bandwidths. (Except when the network is unstable, or there are less than 3 bandwidth authorities.)
-
Replying to teor:
Replying to karsten:
Note the red arrow. At this point
n(H)grows larger thann(N). That's an issue. By definition, a relay cannot report written directory bytes statistics for a longer time than it's online.But relays that aren't listed in the consensus can still be acting as relays.
You're right, there are cases where this is possible. These are just cases we did not consider in the original design of the
fracformula. But yes, this is possible.A possible mitigation (other than the one I suggested above) could be to replace
n(H)withn(N^H)in thefracformula. This would mean that we'd cap the amount of time for which a relay reported written directory bytes to the amount of time it was listed in the consensus.This seems like a reasonable approach: if the relay is listed in the consensus for
n(N^H)seconds, then we should weight its bandwidth using that number of seconds.Oh, you're raising another important point here: speaking in formula terms, if we replace
n(H)withn(N^H)we'll also have to replaceh(H)withh(N^H).Similarly, we'll have to replace
h(R^H)withh(R^H^N)andn(R\H)withn(R^N\H).Hmmmm. I'm less optimistic now that changing the
fracformula is a good idea. It seems like a too big change to make, and we're not even sure that the result will be more accurate.I'm currently dumping and downloading the database to try this out at home. However, I'm afraid that deploying this fix is going to be much more expensive than making the simple fix suggested above. I'll report here what I find out.
I'm not sure if it will make much of a difference long-term: relays that drop out of the consensus should have low bandwidth weights, and therefore low bandwidths. (Except when the network is unstable, or there are less than 3 bandwidth authorities.)
Agreed.
Let's make the change I suggested above, in a slightly modified way:
-WHERE a.frac BETWEEN 0.1 AND 1.0 +WHERE a.frac BETWEEN 0.1 AND 1.1The reason for accepting
fracvalues between1.0and1.1is that, as discussed here, there can be relays reporting statistics that temporarily didn't make it into the consensus.The reason for not giving up on the upper bound is that, as the graph above shows, there are still single days over the years when
fracsuddenly went up to1.2,1.5, or even2.0. We should continue excluding these data points. Therefore we should use1.1as new upper bound.How does this sound?