Refactor hs_service_callback() to no longer need to run once per second?
This is maybe a lot of work, but it would help if we could make all the once-a-second portions of this function into things that we can turn off if we're dormant? I'm hoping for a feature (optional?) where a dormant onion service does the minimum work possible to keep itself online and wait for introductions.
This is a reach task; if we do the rest of the parent ticket, we'll be fine.
Activity
changed milestone to %Tor: unspecified

Trac:
Description: This is maybe a lot of work, but it would help if we could make all the once-a-second portions of this function into things that we can turn off if we're dormant? I'm hoping for a feature (optional?) where a dormant onion service does the minimum work possible to keep itself online and wait for introductions.This is a reach task; if we do the reset of the parent ticket, we'll be fine.
to
This is maybe a lot of work, but it would help if we could make all the once-a-second portions of this function into things that we can turn off if we're dormant? I'm hoping for a feature (optional?) where a dormant onion service does the minimum work possible to keep itself online and wait for introductions.
This is a reach task; if we do the rest of the parent ticket, we'll be fine.

I've thought a bit about this. So the big problem is the hashring which require a fresh consensus in order to compute for each nodes the HSDir index using the SRV value. It doesn't change often (every 24h) but it is also about relay churn impact on the hashring thus it is done as much as we can.
The problem doesn't lie in computing those but rather if we are in a "dormant" state, we don't have a fresh consensus and thus change in SRV or/and churn will affect reachability up to the point of not being reachable (because SRV changed).
We can refactor everything to instead being called every seconds would register a mainloop event in the time frame it needs to be woken up (for instance rotation time of descriptor).
But without a fresh consensus (not participating in the network), we'll run into reachability issues pretty fast.
-
Trac:
Parent: #28335 (moved) to N/A 
If I'm reading the spec right, there are
hsdir_n_replicas = 2replicas. For each replica, the HS uploads the descriptor tohsdir_spread_store = 4HSDirs at consecutive positions in the hashring. Each client tries to fetch the descriptor from one of the firsthsdir_spread_fetch = 3positions, chosen at random.A lookup fails when the position chosen by the client is occupied by an HSDir that didn't receive the descriptor, for both replicas. So failure is possible when any of the first 3 positions is occupied by an HSDir that didn't receive the descriptor, for both replicas. Churn can bring this about in two ways: by removing the HSDirs that received the descriptor, and by adding new HSDirs that push the HSDirs that received the descriptor out of the first 3 positions.
How long do we expect it to take before churn makes a lookup failure possible? We could measure this with historical consensus data, but let's try a quick simulation first.
Figure 9 of this paper shows the fraction of relays with the HSDir flag that join or leave between consecutive consensuses. I'd estimate 0.01 by eye, so let's conservatively call it 0.02. The churn rate counts both joins and leaves, so a churn rate of 0.02 means each HSDir from the previous consensus has left with probability 0.01, and new HSDirs have joined at the same rate.
There are about 3,000 relays with the HSDir flag.
My code (attached) simulates each replica by creating 3,000 HSDirs, each at a random position on the hashring, and remembering the first 4 HSDirs on the hashring - these are the ones that receive copies of the descriptor. Churn is simulated an hour at a time. In each hour, each HSDir is removed with probability 0.01 and replaced with a new HSDir at a random position. Then the code checks whether the first 3 HSDirs on the hashring are all ones that received copies of the descriptor. If not, a lookup on this replica could fail.
For simplicity I've simulated the two replicas independently - in reality they'd be based on different permutations of the same HSDirs, but independence seems like a reasonable approximation. The simulation runs until lookups on both replicas could fail.
The mean time until both replicas could fail is 37 hours, averaged over 10,000 runs.
If this is roughly accurate then we should be able to keep the HS reachable by waking Tor from its dormant state every few hours to fetch a fresh consensus and upload new copies of the descriptor if necessary.
Perhaps I should extend the simulation to consider the probability of lookup failure as a function of time, rather than the mean time until failure becomes possible.
Trac:
Username: akwizgran-
Trac:
Username: akwizgran -
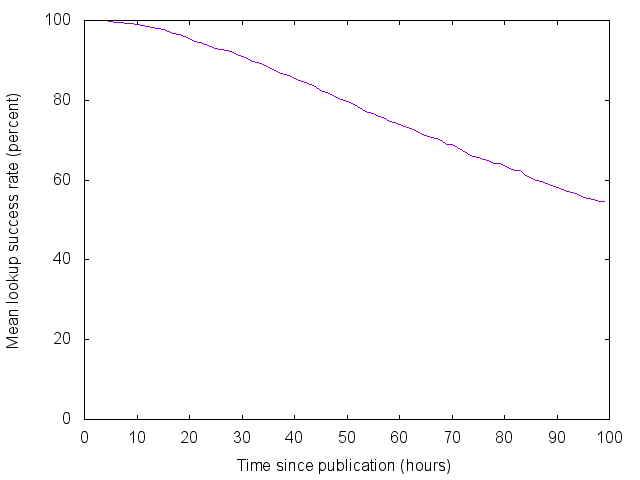
I updated the simulation to consider the probability of lookup failure as a function of time, and to use the same HSDirs in both hashrings. The new code is attached, along with graphs showing the mean and first percentile of the lookup success rate over 1000 independent runs.
The first percentile gives an idea of the experience of an unlucky hidden service. The success rate for an unlucky service falls below 90% after 5 hours, showing that the assessment in my last comment, based on mean time until possible failure, was too optimistic. Services do need to republish their descriptors frequently or there's a significant risk of lookup failure.
Trac:
Username: akwizgran -
Trac:
Username: akwizgran -
At the risk of going off-topic, I just wanted to mention one other thing I noticed when running the simulations. The lookup success rate can be improved by changing the parameters without storing more copies of descriptors.
Reducing
hsdir_spread_fetch, without changing the other parameters, improves the mean lookup success rate. Intuitively, if a replica is stored on dirs d_1...d_n at positions 1...n, churn is less likely to displace d_i from its position than d_{i+1} because there's less hashring distance into which churn could insert a new dir. Thus a client is more likely to find the descriptor at position i than position i+1 after churn. Reducinghsdir_spread_fetchconcentrates more of the client's lookups on positions that are more likely to hold the descriptor.However, while the mean lookup success rate is improved, the effect on the first percentile is more nuanced. The success rate remains at 100% for longer, but then falls faster. I think this is because each lookup chooses from a smaller set of positions to query, so there's a smaller set of possible outcomes. When
hsdir_spread_fetch == 1, all lookups query the same positions.This is relevant in the real world if clients can retry failed lookups. We might accept a lower mean success rate if clients can have another chance at success by retrying.
Another interesting possibility is to trade a larger
hsdir_n_replicasfor a smallerhsdir_spread_store. In other words, use more replicas and store fewer copies at each replica. This improves the lookup success rate (both mean and first percentile), without increasing the number of copies of the descriptor that are stored.However, I'm not sure how increasing
hsdir_n_replicaswould affect query bandwidth. Do clients try replicas in parallel or series? If parallel, increasinghsdir_n_replicaswould increase bandwidth for all queries. If series, the worst-case bandwidth would increase (a query would visit more replicas before failing).Trac:
Username: akwizgran moved to tpo/core/tor#28424 (closed)